La presente reseña está basada en el capítulo “Capa de Transporte” del libro Redes de Computadoras en su 3ª edición, publicado por el investigador Andrew S. Tanenbaum, quien actualmente se desempeña como profesor de la Vrije Universiteit de Amsterdam, Paises Bajos y ganador de números premios a su trabajo.
El presente trabajo trata sobre el protocolo de transporte TCP, el cual se encuentra diseñado específicamente para proporcionar una transmisión de datos fiable en un sistema de comunicaciones, dicha fiabilidad está basada principalmente en un número de reconocimiento (ack), un tiempo de vida y un control de error (checksum) en cada paquete transmitido para determinar si debe o no debe ser enviado de vuelta a través de la red.
Palabras clave: paquete, protocolo, puerto.
This work treats about the TCP protocol, which has been specifically designed to provide a reliable data transmission in a communication system, this reliability is based principally on the acknowledgement number (ack), alive time and error control (checksum) on every packet transmitted to determine if it should or should not be sent back through the network.
Keywords: packet, protocol, port.
El protocolo TCP se definió en el RFC 793. A medida que pasó el tiempo, se detectaron varios errores e inconsistencias, y se cambiaron los requisitos de algunas áreas. En el RFC 1323 se presentan las extensiones y algunas correcciones de fallas se detallan en el RFC 1122. En el RFC 1323 se presentan las extensiones.
Cada máquina que reconoce al protocolo TCP tiene una entidad de transporte TCP, ya sea un proceso de usuario o una parte del núcleo que maneja las corrientes TCP y tiene interfaz con la IP.
Una entidad TCP acepta corrientes de datos de usuario de los procesos locales, los divide en partes que no exceden 64 Kbytes (en la práctica, generalmente de unos 1500 bytes), y envía cada parte como datagrama IP independiente. Cuando llegan a una maquina datagramas IP que contienen datos TCP, son entregados a la entidad TCP, que reconstruye las corrientes originales de bytes.
El servicio TCP se obtiene haciendo que tanto el emisor como el receptor creen puntos terminales, llamados sockets. Cada socket tiene un número descriptor que consiste en la dirección IP del host y un número de 16 bits local a ese host, llamado puerto. Para obtener el servicio TCP, debe establecerse explícitamente una conexión entre un socket de la maquina transmisora y un socket de la maquina receptora.
Puede usarse un socket para varias conexiones al mismo tiempo. En otras palabras, dos o más conexiones pueden terminar en el mismo socket.
El protocolo TCP es orientado a conexión y fiable debido a las siguientes razones:
a) Orientado a conexión. Obliga establecer una conexión previa entre las dos máquinas antes de poder transmitir algún dato. A través de esta conexión los datos llegarán siempre a la aplicación destino de forma ordenada y sin duplicados. Finalmente, es necesario cerrar la conexión.
b) Fiable. La información que envía el emisor llega de forma correcta al destino. El protocolo TCP permite una comunicación fiable entre dos aplicaciones. De esta forma, las aplicaciones que lo utilicen no tienen que preocuparse de la integridad de la información: dan por hecho que todo lo que reciben es correcto.
Cada byte de una conexión TCP tiene su propio número de secuencia de 32 bits. En un host que opera a toda velocidad en una LAN de 10 Mbps, en teoría los números de secuencia podrían volver a comenzar en una hora, pero en la práctica tarda mucho más tiempo. Se usan los números de secuencia tanto para los acuses de recibo como para el mecanismo de ventana, que utilizan campos de cabecera de 32 bits distintos.
La entidad TCP transmisora y la receptora intercambian datos en forma de segmentos. Un segmento consiste en una cabecera TCP fija de 20 bytes (más una parte opcional) seguida de cero o más bytes de datos. El software de TCP decide el tamaño de los segmentos y puede acumular datos de varias escrituras para formar un segmento, o dividir los datos de una escritura en varios segmentos. Hay dos límites que restringen el tamaño de segmento. Primero, cada segmento, incluida la cabecea TCP debe caber en la carga útil de 65,535 bytes del IP. Segundo, cada red tiene una unidad máxima de transferencia, o MTU (máximum transfer unit) y cada segmento debe caber en la MTU. En la práctica, las MTU generalmente son de unos cuantos miles de bytes y por tanto defienden el límite superior del tamaño de segmento. Si un segmento pasa a través de una serie de redes sin fragmentarse y luego se topa con una cuya MTU es menor que el segmento, el enrutador de la frontera fragmenta y luego se topa con una cuya MTU es menor que el segmento, el enrutador de la frontera fragmenta el segmento en dos o más segmentos más pequeños.
Un segmento demasiado grande para transitar por una red puede dividirse en varios segmentos mediante un enrutador. Cada segmento nuevo recibe sus propias cabeceras TCP e IP, por lo que la fragmentación en los enrutadores aumenta la carga extra total (puesto que cada segmento adicional agrega 40 bytes de información de cabecera).
TCP debe estar preparado para manejar y resolver estos problemas de una manera eficiente. Se ha invertido una cantidad considerable de esfuerzo en la optimización del desempeño de las corrientes TCP, incluido ante problemas de red.
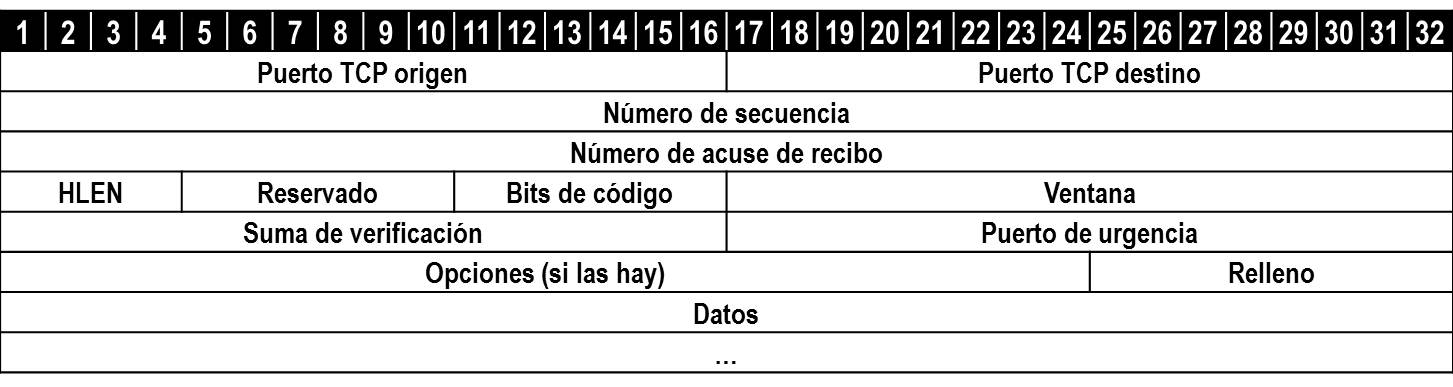
Como sabemos, el flujo de información se divide en uno o más segmentos con el fin de que la información viaje a través de la red, estos segmentos son enumerados para así facilitar su desempaquetamiento, en la tabla se muestra la estructura de TCP.
Puerto fuente (16 bits). Puerto de la máquina origen. Al igual que el puerto destino es necesario para identificar la conexión actual.
Puerto destino (16 bits). Puerto de la máquina destino.
Número de secuencia (32 bits). Indica el número de secuencia del primer byte que trasporta el segmento.
Número de acuse de recibo (32 bits). Indica el número de secuencia del siguiente byte que se espera recibir. Con este campo se indica al otro extremo de la conexión que los bytes anteriores se han recibido correctamente.
HLEN (4 bits). Longitud de la cabecera medida en múltiplos de 32 bits (4 bytes). El valor mínimo de este campo es 5, que corresponde a un segmento sin datos (20 bytes).
Reservado (6 bits). Bits reservados para un posible uso futuro.
Bits de código o indicadores (6 bits). Los bits de código determinan el propósito y contenido del segmento. A continuación se explica el significado de cada uno de estos bits (mostrados de izquierda a derecha) si está a 1.
URG. El campo puntero de urgencia contiene información válida.
ACK. El campo número de acuse de recibo contiene información válida, es decir, el segmento actual lleva un ACK. Un mismo segmento puede transportar los datos de un sentido y las confirmaciones del otro sentido de la comunicación.
PSH. La aplicación ha solicitado una operación push (enviar los datos existentes en la memoria temporal sin esperar a completar el segmento).
RST. Interrupción de la conexión actual.
SYN. Sincronización de los números de secuencia. Se utiliza al crear una conexión para indicar al otro extremo cual va a ser el primer número de secuencia con el que va a comenzar a transmitir.
FIN. Indica al otro extremo que la aplicación ya no tiene más datos para enviar. Se utiliza para solicitar el cierre de la conexión actual.
Ventana (16 bits). Número de bytes que el emisor del segmento está dispuesto a aceptar por parte del destino.
Suma de verificación (24 bits). Suma de comprobación de errores del segmento actual. Para su cálculo se utiliza una pseudo-cabecera que también incluye las direcciones IP origen y destino.
Puntero de urgencia (8 bits). Se utiliza cuando se están enviando datos urgentes que tienen preferencia sobre todos los demás e indica el siguiente byte del campo Datos que sigue a los datos urgentes. Esto le permite al destino identificar donde terminan los datos urgentes. Nótese que un mismo segmento puede contener tanto datos urgentes (al principio) como normales (después de los urgentes).
Opciones (variable). Si está presente únicamente se define una opción: el tamaño máximo de segmento que será aceptado.
Relleno. Se utiliza para que la longitud de la cabecera sea múltiplo de 32 bits.
Datos. Información que envía la aplicación.
TCP usa varios temporizadores para hacer su trabajo. El más importante de estos es el temporizador de retransmisión. Al enviarse un segmento, se inicia un temporizador de retransmisiones. Si el acuse de recibo llega antes de expirar el temporizador, este se detiene, Si por otra parte, el temporizador termina antes de llegar el acuse de recibo, se retransmite el segmento (y se inicia nuevamente el temporizador). Surge entonces la pregunta: ¿Qué tan grande debe ser el intervalo de terminación del temporizador?
Este problema es mucho más difícil en la capa de transporte de internet que en los protocolos de enlace de datos. En este último caso, el retardo esperado es altamente predecible (es decir, tiene una variación baja), por lo que el temporizador puede ajustarse para terminar justo después que los acuses de recibo pocas veces se retrasan en la capa de enlace de datos, la ausencia de un acuse de recibo en el momento esperado generalmente significa que el marco o el acuse de recibo se han perdido.
Es complicada la determinación de tiempo de ida y vuelta al destino. Aun cuando se conoce, la sección del intervalo de terminación de temporización también es difícil. Si se hace demasiado corto, digamos T1 ocurrirían retransmisiones innecesarias, cargando la Internet con paquetes inútiles. Si se hace demasiado largo T2, el desempeño sufrirá debido al gran retardo de retransmisión de cada paquete perdido. Es más, la varianza y la media de la distribución de llegadas de acuse de recibo pueden variar con rapidez en unos cuantos segundos a medida que se generan y se resuelven congestionamientos.
La solución está basada un algoritmo dinámico que ajusta constantemente el intervalo de terminación de temporización, con base en mediciones continuas del desempeño de la red. El algoritmo que generalmente usa TCP se debe a Jacobson (1988) y funciona como sigue. Por cada conexión, TCP mantiene una variable, RTT (round-trip time), que es la mejor estimación actual del tiempo de ida y vuelta al destino en cuestión. Al enviarse un segmento, se inicia un temporizador, tanto para ver el tiempo que tarda el acuse de recibo como para disparar una retransmisión si se tarda demasiado. Si llega el acuse de recibo antes de expirar el temporizador, TCP mide el tiempo que tardo el acuse de recibo.
El segundo temporizador es el temporizador de persistencia, diseñado para evitar el siguiente interbloqueo. El receptor envía un acuse de recibo con un tamaño de ventana de 0, indicando al transmisor que espere. Después, el receptor actualiza la ventana, pero se pierde el paquete con la actualización. Ahora, tanto el transmisor como el receptor están esperando que el otro haga algo. Cuando termina el temporizador de persistencia, el transmisor envía una prueba al receptor. La respuesta de la prueba indica el tamaño de la ventana. Si aún es de cero, se inicia el temporizador de persistencia, repitiéndose el ciclo. Si es diferente de cero, pueden enviarse datos.
Un tercer temporizador usado en algunas implementaciones es el temporizador de seguir con vida (keepalive timer). Cuando una conexión ha estado ociosa durante demasiado tiempo, el temporizador de seguir con vida puede terminar, haciendo que un lado compruebe que el otro aún está ahí. Si no se recibe respuesta, se termina la conexión por lo demás saludable debido a una partición temporal de la red.
El último temporizador usado en cada conexión TCP es el que se usa en estado TIMED WAIT durante el cierre, el cual opera durante el doble del tiempo de vida de paquete para asegurar que, al cerrarse una conexión, todos los paquetes creados por ella hayan muerto.
Antes de transmitir cualquier información utilizando el protocolo TCP es necesario abrir una conexión. Un extremo hace una apertura pasiva y el otro, una apertura activa. El mecanismo utilizado para establecer una conexión consta de tres vías.
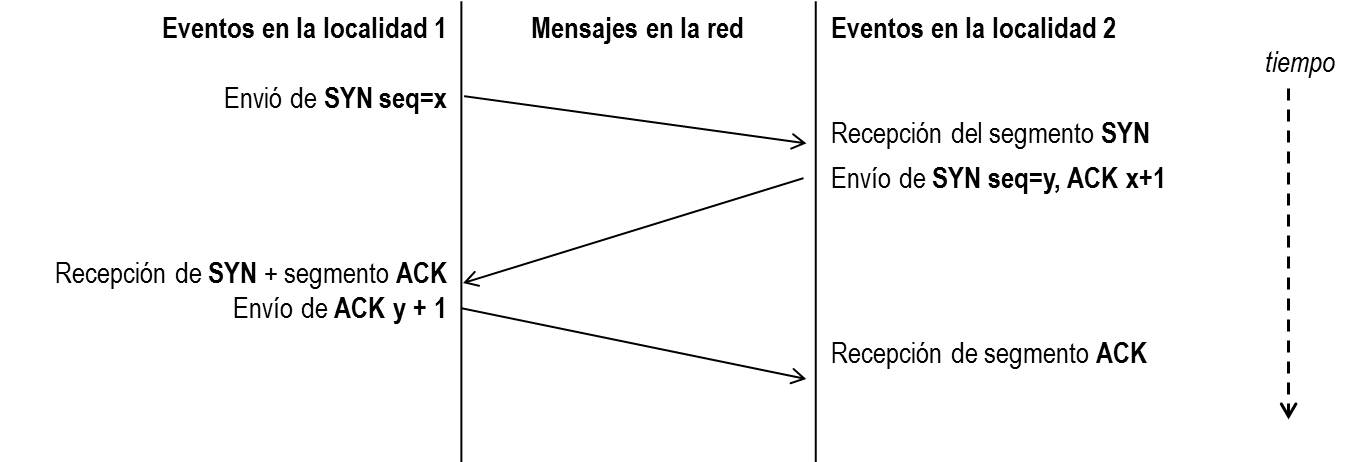
La máquina que quiere iniciar la conexión hace una apertura activa enviando al otro extremo un mensaje que tenga el bit SYN activado. Le informa además del primer número de secuencia que utilizará para enviar sus mensajes.
La máquina receptora (un servidor generalmente) recibe el segmento con el bit SYN activado y devuelve la correspondiente confirmación. Si desea abrir la conexión, activa el bit SYN del segmento e informa de su primer número de secuencia. Deja abierta la conexión por su extremo.
La primera máquina recibe el segmento y envía su confirmación. A partir de este momento puede enviar datos al otro extremo. Abre la conexión por su extremo.
La máquina receptora recibe la confirmación y entiende que el otro extremo ha abierto ya su conexión. A partir de este momento puede enviar ella también datos. La conexión ha quedado abierta en los dos sentidos.
Observamos que son necesarios 3 segmentos para que ambas máquinas abran sus conexiones y sepan que la otra también está preparada.
Números de secuencia. Se utilizan números de secuencia distintos para cada sentido de la comunicación. Como hemos visto el primer número para cada sentido se acuerda al establecer la comunicación. Cada extremo se inventa un número aleatorio y envía éste como inicio de secuencia.
Observamos que los números de secuencia no comienzan entonces en el cero. ¿Por qué se procede así? Uno de los motivos es para evitar conflictos: supongamos que la conexión en un ordenador se interrumpe nada más empezar y se crea una nueva. Si ambas han empezado en el cero es posible que el receptor entienda que la segunda conexión es una continuación de la primera (si utilizan los mismos puertos).
Cierre de una conexión. Cuando una aplicación ya no tiene más datos que transferir, el procedimiento normal es cerrar la conexión utilizando una variación del mecanismo de 3 vías explicado anteriormente.
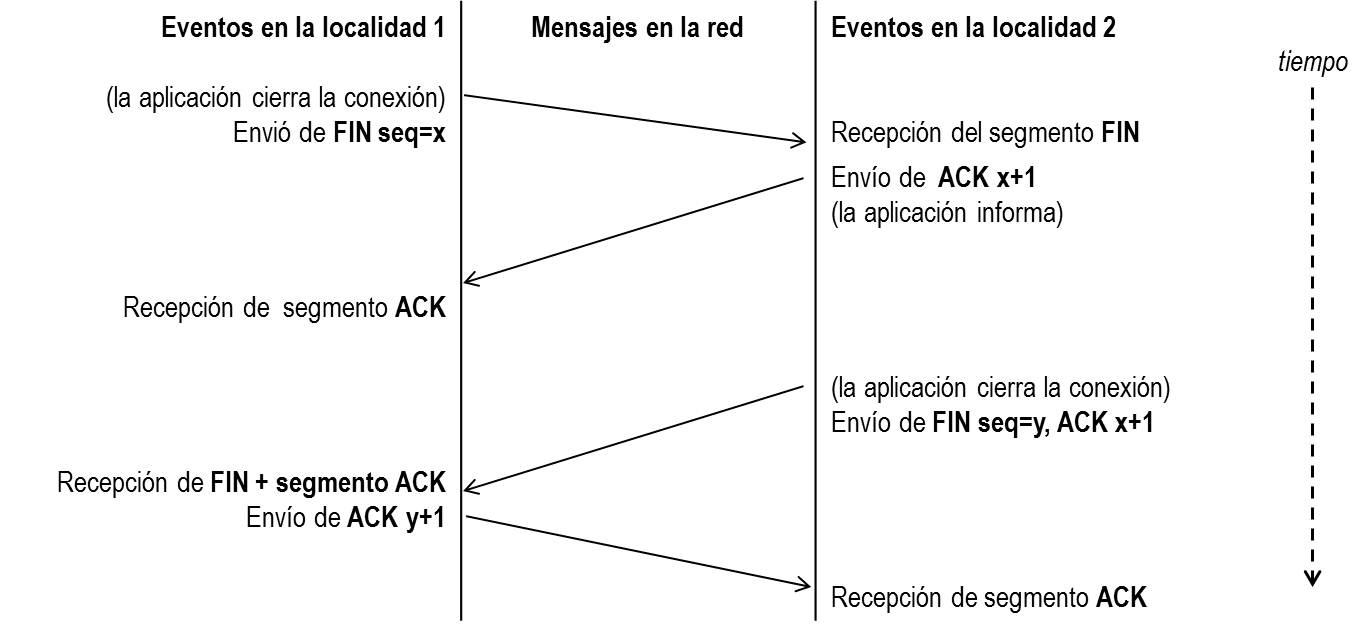
El mecanismo de cierre es algo más complicado que el de establecimiento de conexión debido a que las conexiones son full-dúplex y es necesario cerrar cada uno de los dos sentidos de forma independiente.
La máquina que ya no tiene más datos que transferir, envía un segmento con el bit FIN activado y cierra el sentido de envío. Sin embargo, el sentido de recepción de la conexión sigue todavía abierto.
La máquina receptora recibe el segmento con el bit FIN activado y devuelve la correspondiente confirmación. Pero no cierra inmediatamente el otro sentido de la conexión sino que informa a la aplicación de la petición de cierre. Aquí se produce un lapso de tiempo hasta que la aplicación decide cerrar el otro sentido de la conexión.
La primera máquina recibe el segmento ACK. Cuando la máquina receptora toma la decisión de cerrar el otro sentido de la comunicación, envía un segmento con el bit FIN activado y cierra la conexión.
La primera máquina recibe el segmento FIN y envía el correspondiente ACK. Observemos que aunque haya cerrado su sentido de la conexión sigue devolviendo las confirmaciones. La máquina receptora recibe el segmento ACK.
El protocolo TCP utiliza la noción de números de acceso para identificar enviar y la recepción de límites del uso en un anfitrión, o Zócalos del Internet.
Cada lado de una conexión TCP tiene un número de acceso sin firmar asociado de 16 bits (1-65535) reservado por el uso que envía o de recepción. Los paquetes de datos que llegan son identificados mediante una conexión TCP específica, que consta de una combinación de la dirección IP y número de puerto, tanto del host origen como del host destino.
Esto significa que un servidor puede proveer de varios clientes varios servicios a la vez, mientras el cliente toma cuidado de iniciar cualquier conexión simultánea con números de puerto diversos.
Los números de acceso se recaen en tres categorías básicas: puertos bien conocidos, registrados, y dinámicos/privados.
Los puertos bien conocidos. Oscila entre 0 y 1023. Son asignados por Internet Assigned Numbers Authority (IANA) y son utilizados típicamente por procesos a nivel sistema o de la raíz. Entre los que se encuentran: ftp (21), ssh (22), telnet (23), smtp (25) y http (80).
Los puertos registrados. Oscilan entre 1024 a 49151 y pueden ser usados de manera temporal por los clientes, pero también pueden representar servicios registrados por un tercero.
Los puertos dinámicos o privados. Oscilan entre 49152 y 65535. Se pueden también utilizar por usos del usuario final, pero son menos comunes.
Crítica
El protocolo TCP es adecuado para utilizarse en redes pequeñas y grandes debido a que tiene un alto grado de fiabilidad, sin embargo, resulta algo lento en redes con tráfico mediano, debido a que su diseño le obliga a constatar que los datos transmitidos realmente hayan sido recibidos en tiempo y con integridad.
Andrew S. Tanenbaum. Redes de computadoras. 3ª edición, Prentice Hall, pag 521 – 542.
Waseem M. Haider, Erik Nieto Tovar, Hugo E. Camacho Cruz, Raúl Hernández Palacios. Estudio Detallado de Comunicación sobre TCP/IP y Comparación con el protocolo CLIC. Universidad De Granada, pag 4-6.
[a] Profesor por asignatura, Escuela Superior Huejutla de la Universidad Autónoma del Estado de Hidalgo.