El presente trabajo trata sobre el uso de un algoritmo de agrupamiento k-means, utilizado para encontrar los k grupos más representativos de una colección de datos provenientes de una BD, la intención de utilizar este algoritmo radica en el interés por determinar los niveles de reforestación en la República Mexicana durante el transcurso del periodo 1994-2011, tomando como fuente de información fidedigna un banco de datos proporcionados por INEGI. Se detallan los procedimientos para resolver el problema utilizando un software de aprendizaje automático específico para la minería de datos (WEKA, Waikato Environment For Knowledge Analysis).
Palabras clave: WEKA, Algoritmo K-means, Base de Datos, Minería de datos.
This paper discusses the use of a clustering algorithm k-means, k used to find the most representative groups of a collection of data from a BD, the intention of using this algorithm it lies in the interest of determining levels of reforestation in Mexico during the period 1994-2011, taking as a source of reliable information a database provided by INEGI. Detailed procedures to solve a given problem using machine learning software and Weka data mining problem.
Keywords: Weka, K-means algorithm, Data Base, Data Mining.
Los métodos de clúster, también llamados de segmentación de datos, tiene como finalidad agrupar o segmentar una colección de objetos en subconjuntos o clusters, de manera que dentro de cada grupo compartan características estrechamente similares que con los que están en diferente grupo [1], tal es el caso del algoritmo de agrupamiento K- means dada su simplicidad y eficiencia es fácil de entender e implementar [2]. Asociado a ello se documenta a continuación la metodología para resolver un problema con objetos reales extraídos de una Base de Datos INEGI.
K-means o K-medias es uno de los algoritmos más utilizados para realizar agrupamiento, técnica implementada en Minería de Datos. La idea del k-medias es colocar todos los objetos en un espacio determinado y dadas sus características formar grupos de objetos con rasgos similares pero diferentes a los demás que integran otros grupos.
Sin embargo el algoritmo presenta algunos inconvenientes:
• El agrupamiento final depende de los centroides iniciales.
• La convergencia en el óptimo global no está garantizada, y para problemas con muchos ejemplares, requiere de un gran número de iteraciones para converger [3].
Descripción del algoritmo k-means
Paso 1. Inicialización: Se definen un conjunto de objetos a los cuales se les aplica el proceso de clustering que consiste en la división de los datos en grupos y un centroide (centro geométrico del clusters) para cada uno. Los centroides iniciales se pueden determinar aleatoriamente, mientras que en otros casos procesan los datos y se determinan los centroides mediante cálculos.
Paso 2. Clasificación: Para cada dato se calcula la distancia (euclidiana cuadrada) con respecto a los centroides, se determina el centroide más cercano a cada uno de los datos, y el objeto se anexa al clusters del centroide que fue seleccionado.
Paso 3. Calculo de centroides: Para cada uno de los clusters se vuelve a recalcular los centroides.
Paso 4. Verificación de convergencia: En este paso se comprueba si una de las condiciones del algoritmo se ha cumplido y que este debe parar, a esto se le llama condición de convergencia o paro. A continuación se mencionan algunas de las condiciones de convergencia:
a) El número de iteraciones.
b) Cuando los centroides obtenidos en dos iteraciones sucesivas no cambian su valor.
c) Cuando la diferencia entre los centroides de dos iteraciones sucesivas no supera cierto umbral.
d) Cuando no hay transferencia de objetos entre grupos en dos iteraciones sucesivas [5].
Si algunas de las condiciones de convergencia no cumplen se repiten los pasos dos, tres y cuatro del algoritmo.
Variantes del algoritmo K-means
Las variantes del k-means son ramificaciones que particionan un conjunto de datos en clusters, a continuación describen cada una:
K –medianas: Este algoritmo funciona de forma similar al k-means y es también sensible a la selección de centroides iniciales, continua sustituyendo el valor de promedios por el vector de medianas del grupo de datos y utiliza una distancia manhattan como una medida de disimilitud.
K-medoids: Fue introducido por Kaufman y Rousseeuw en 1987 [6]. Este algoritmo está basado en un conjunto de datos localizados muy en el centro de cada clusters, los puntos restantes del grupo son agrupados con el medoids más cercano.
Iterativamente este algoritmo realiza intercambios entre los datos representativos y los que no lo son, hasta que minimice una diferencia entre lo k –medoids y los vectores que forman los clustering.
Fuzzy c-means: Es un algoritmo que fue desarrollado para solucionar los datos que pueden pertenecer parcialmente a más de un clusters. FCM realiza una partición suave del conjunto de datos, un tipo de partición suave especial es aquella en la que la suma de los grados de pertenencia de un punto específico en todos los clusters es igual a 1 [7].
El proceso de desarrollo se maneja en dos etapas utilizando WEKA (Waikato Environment for Knowledge Analysis), la cual ofrece una colección muy variada de algoritmos de aprendizaje automático para tareas de minería de datos escrito en Java y desarrollado por la Universidad de Waikato [4].
1. Planteamiento del problema.
En la República Mexicana se llevan a cabo campañas de reforestación por estados, el ciclo 1994- 2011 se monitoreo el nivel de actividad en cada entidad federativa, y con respecto a esta información se desea saber qué estado tuvo una mayor productividad a lo largo de este periodo, misma que queda descrita en los puntos subsecuentes.
2. Exploración de archivos.
En esta fase se asume el procesamiento de datos con WEKA para ello se utiliza conjunto de datos de la muestra proporcionados por INEGI en un registro "BIINEGI_BIINEGI20150504171232.csv " el cual contiene 31 casos, uno por entidad federativa.
2.1 Al ejecutar la herramienta WEKA, aparece en pantalla un menú con cuatro opciones.
2.2 Se selecciona la opción "Explorer" para tener acceso a una nueva ventana donde se despliegan nuevas opciones.
Algunas implementaciones de K-means solo permiten valores numéricos para los atributos. En este caso, puede ser necesario convertir los datos establecidos en el formato de hoja de cálculo a atributos categóricos en binario. En otros casos es importante normalizar los valores de los atributos que se miden sustancialmente en diferentes escalas. Para el caso de estudio planteado en este documento, se cuenta con dos atributos "la clave de la entidad federativa" y "la clave del municipio".
Mientras WEKA ofrece filtros para lograr todas estas tareas de pre procesamiento, no son esenciales para el agrupamiento, esto se debe a que el algoritmo se encarga de automatizar una mezcla de atributos categóricos y numéricos. Además el algoritmo normaliza automáticamente los atributos numéricos para llevar acabo los cálculos de distancia.
2.3 La opción que permite la exploración de archivos es "option file" la cual accede a una ventana secundaria para poder importar el archivo necesario para llevar a cabo el análisis. Posteriormente se aplica un filtro para ubicar archivos con la extensión ".csv".
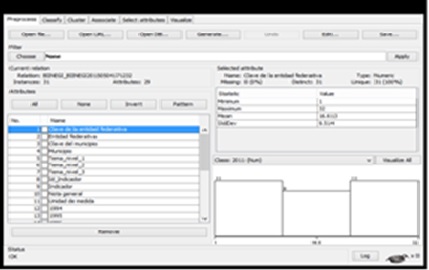
2.4 A continuación, se importa el archivo que lleva por nombre BIINEGI_BIINEGI20150504171232.csv” y sus datos se muestran en pantalla, como se observa en la Figura 1.
Figura 1 Datos del archivo importado en la ventana de Weka Explorer
3. Análisis de datos.
3.1 Una vez importada la base de datos se lleva a cabo la agrupación de los datos, en la herramienta WEKA, se mostrara una pantalla con seis opciones.
3.2 Selecciona la pestaña "Cluster". Esta opción permite elegir el algoritmo de agrupación k-means.
Se visualizara en la pantalla una lista de algoritmos de clustering y se optara por "SimpleKmeans".
3.3 Dar un clic en el botón de "Start" y mostrara una ventana emergente la cual permite editar el número de grupos para la realización del algoritmo de clusters.
3.4 El número de clusters para la representación de los niveles de reforestación de la República Mexicana durante el transcurso del periodo 1994-2011, será de dos grupos, como se muestra en la Figura 2.
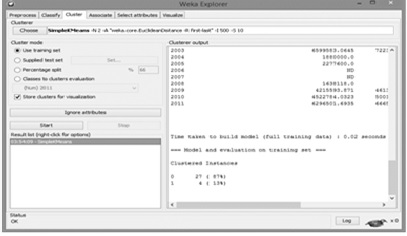
Figura 2 Selección del algoritmo K- means y el número de clusters.
Como k-means es sensible asignación de clusters es necesario probar diferentes valores y evaluar los resultados.
3.5 Una vez que se asignó el número de grupos se ejecuta el algoritmo de agrupamiento.
3.6 Dentro de la pantalla en el panel de "Cluster Mode”, selecciona la opción de "use training set" y se da clic en el botón "Start".
Seleccionar la opción "Result list" y se mostrarán los resultados de la agrupación en una pantalla, en el cual puede apreciarse el centroide de cada cluster encontrado.
3.7 Los centroides son utilizados para caracterizar a cada uno de los grupos que se muestran. Para ver la representación gráfica de los clusters con sus respectivos centroides, se selecciona "Result list" y en la parte izquierda del panel se elige "Visualize cluster assignments", esto se puede visualizar en la figura 3.
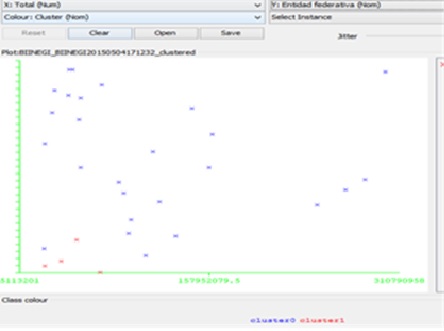
Figura 3 Representación gráfica de los clusters.
En la herramienta WEKA se puede elegir para cada una de las tres dimensiones; eje x, eje y, y el color, los cuales resultaran en una representación visual.
Finalmente el trabajo se enfocó en analizar y realizar las iteraciones necesarias hasta encontrar los grupos con sus respectivos centroides que representen los niveles de reforestación Mexicana de los estados de la Republica durante el transcurso del periodo 1994-2011.
De un total de 31 estados que representan en su totalidad el 100%, se determinó que el clusters número 0 obtuvo un total de 27 estados con mayor reforestación posicionándose como el grupo más significativo con respecto a los demás con un porcentaje de 87%.
Mientras que el clusters 1 obtuvo un total de 4 estados con menor índice de reforestación con un porcentaje de 13%,
[1]Departamento de Matematica Facultad de Ciencias Exactas y Naturales Universidad de Buenos Aires. Recuperado el 08 de Mayo de 2015, de Departamento de Matematica Facultad de Ciencias Exactas y Naturales Universidad de Buenos Aires: http://cms.dm.uba.ar/academico/carreras/licenciatura/tesis/2010/ Gimenez_Yanina.pdf
[2]Repositorio Institucional de la Universidad Nacional de la Plata. Recuperado el 09 de Mayo de 2015, de Repositorio Institucional de la Universidad Nacional de la Plata: http://sedici.unlp.edu.ar/bitstream/handle/10915/26772/Documento_ completo.pdf?sequence=1
[3]Universidad Carlos III. Recuperado el 10 de Mayo de 2015, de Universidad Carlos III: http://www.it.uc3m.es/jvillena/irc/practicas/09-10/19mem.pdf
[4]WEKA The University of Waikato. Obtenido de WEKA The University of Waikato: http://www.cs.waikato.ac.nz/ml/weka/
[5]Centro Nacional de Investigacion y Desarrollo Tecnologico. Recuperado el 12 de Mayo de 2015, de Centro Nacional de Investigacion y Desarrollo Tecnologico: http://www.cenidet.edu.mx/subplan/biblio/seleccion/Tesis/ MC%20Rosy%20Ilda%20Basave%20Torres%202005.pdf
[6](2 de Diciembre de 2010). Universidad Nacional de Colombia. Recuperado el 12 de Mayo de 2015, de Universidad Nacional de Colombia: http://www.scielo.org.co/scielo.php?script=sci_arttext pid=S0120-17512010000200009
[7](2008). Dialnet. Recuperado el 13 de Mayo de 2015, de Dialnet: dialnet.unirioja.es/descarga/articulo/4742189.pdf
[a] Profesor por asignatura de la Universidad Autónoma del Estado de Hidalgo
[b] Alumnos de la Lic. en Sistemas Computacionales.