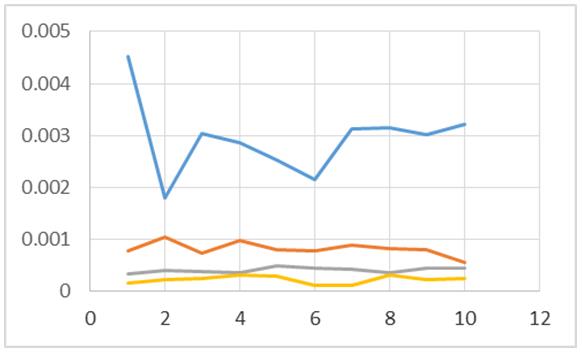
Figura 1: Algoritmos con N=100
Para elegir un algoritmo de acuerdo a la eficiencia que éste tiene, entre algunos aspectos se consideran principalmente dos; la complejidad temporal y la complejidad espacial. La complejidad temporal es la mayormente empleada como criterio de selección al considerar el tamaño de los datos de entrada que procesará el algoritmo, siendo obvio que mientras más datos se tengan que procesar mayor es el tiempo que el algoritmo necesitará para procesarlos. Sin embargo, técnicas como la concurrencia y el paralelismo pueden ser empleados para mejorar el tiempo requerido para obtener los resultados de un algoritmo.
Palabras clave: Concurrencia, paralelismo, cómputo de alto desempeño, algoritmos, Python, GPU.
Dentro de las actividades que realiza el ser humano en el día con día, hay tareas que se realizan y de las cuales es posible descomponerlas en subtareas que pueden llevarse a cabo de manera simultánea, obteniendo así el mismo resultado que si se hubieran realizado de manera secuencial. A lo anterior se le denomina procesamiento en paralelo.
El procesamiento en paralelo también contiene pasos que deben realizarse de manera secuencial, aún y cuando puedan llevarse a cabo por separado y se obtenga así el resultado deseado.
Un ejemplo del paralelismo que es posible encontrar de manera cotidiana se presenta dentro de las expresiones algebraicas y/o aritméticas, donde al momento de pretender dar solución a la expresión es posible encontrar partes de ella que pueden ser realizadas de manera simultánea.
La ventaja palpable del empleo de procesamiento en paralelo es el ahorro de tiempo que se logra al momento de realizar alguna tarea, además de que de manera directa, se hace un mejor uso de los recursos computacionalmente hablando.
Para lograr el paralelismo se necesitan más de una instancia que permita que las cosas se hagan al mismo tiempo, como por ejemplo contar con más de un procesador dentro del equipo de cómputo. El inconveniente de lo anterior es que de manera habitual se encuentran equipo de cómputo, que a lo mucho solo permite procesar las tareas a través de la multitarea (ya que el equipo solo posee un procesador), que no es otra cosa que se realicen las cosas “al mismo tiempo”. Se entrecomillan las palabras dado que en la multitarea solo se le destina fracciones de tiempo para realización de varias tareas, dando la impresión de que se están realizando las cosas al mismo tiempo sin serlo. Es decir, en un sentido computacional se puede tener procesamiento en paralelo con procesamiento concurrente.
Considerando la premisa anterior, es posible desarrollar en equipos de cómputo convencionales (computadoras personales y/o computadoras portátiles) tareas donde se requiera minimizar el tiempo requerido para su realización, sin necesidad de hacerlo en equipos sofisticados y con grandes recursos.
Dentro de las actividades que realiza el ser humano en el día con día, hay tareas que se realizan y de las cuales es posible descomponerlas en subtareas que pueden llevarse a cabo de manera simultánea, obteniendo así el mismo resultado que si se hubieran realizado de manera secuencial. A lo anterior se le denomina procesamiento en paralelo.
El procesamiento en paralelo también contiene pasos que deben realizarse de manera secuencial, aún y cuando puedan llevarse a cabo por separado y se obtenga así el resultado deseado.
Un ejemplo del paralelismo que es posible encontrar de manera cotidiana se presenta dentro de las expresiones algebraicas y/o aritméticas, donde al momento de pretender dar solución a la expresión es posible encontrar partes de ella que pueden ser realizadas de manera simultánea.
La ventaja palpable del empleo de procesamiento en paralelo es el ahorro de tiempo que se logra al momento de realizar alguna tarea, además de que de manera directa, se hace un mejor uso de los recursos computacionalmente hablando.
Para lograr el paralelismo se necesitan más de una instancia que permita que las cosas se hagan al mismo tiempo, como por ejemplo contar con más de un procesador dentro del equipo de cómputo. El inconveniente de lo anterior es que de manera habitual se encuentran equipo de cómputo, que a lo mucho solo permite procesar las tareas a través de la multitarea (ya que el equipo solo posee un procesador), que no es otra cosa que se realicen las cosas “al mismo tiempo”. Se entrecomillan las palabras dado que en la multitarea solo se le destina fracciones de tiempo para realización de varias tareas, dando la impresión de que se están realizando las cosas al mismo tiempo sin serlo. Es decir, en un sentido computacional se puede tener procesamiento en paralelo con procesamiento concurrente.
Considerando la premisa anterior, es posible desarrollar en equipos de cómputo convencionales (computadoras personales y/o computadoras portátiles) tareas donde se requiera minimizar el tiempo requerido para su realización, sin necesidad de hacerlo en equipos sofisticados y con grandes recursos.
La importancia que está tomando el cómputo de alto desempeño (HPC) está siendo cada vez mayor debido al abaratamiento del hardware y la incorporación de éste en los nuevos equipos de cómputo. De esta manera se pueden implementar algoritmos cuya entrada de datos N puede ser bastante grande a través del cual se pueda obtener la simulación de procesos lo más cercano a la realidad debido al modelado que puede hacerse en la unidad básica que represente un problema. El modelado se realiza al momento de generar el algoritmo que permita describir un comportamiento dadas las condiciones iniciales del problema y los valores de frontera correspondientes, de acuerdo a la interacción de dicha unidad con otras.
Para esto, en el presente artículo se realizará la revisión de un algoritmo simple (sin el empleo de hilos o threads) cuyo objetivo es el de ordenar N números enteros que van desde el rango de 1 a 5000 generados de manera aleatoria, de tal manera que pueda realizarse la medición del tiempo que requiere el algoritmo para tener la lista ordenada en su totalidad. Para esta revisión se propone el uso de hilos de manera tal que pueda llevarse a cabo la manipulación de los datos a través de concurrencia en el equipo de cómputo.
El equipo de cómputo donde el algoritmo fue programado y ejecutado para su revisión posee las características de hardware y software descritas en la Tabla 1.
| Característica | Descripción |
| Lenguaje de programación empleado | Python 3.4 |
| Sistema operativo | Ubuntu 14.04 |
| Versión del sistema operativo | Linux 3.13.0-37-generic |
| Tipo de sistema operativo | 64 bits |
| Procesador | Intel Core I5 |
| Velocidad | 2.67 Ghz |
| Memoria RAM | 4 GB |
Los resultados a mostrar se obtuvieron realizando la ejecución del algoritmo en diez ocasiones con el mismo número de datos y todos ellos generados de manera aleatoria para determinar los tiempos mínimos, máximos y el promedio entre ellos. La tabla 2 muestra los tiempos correspondientes obtenidos y el tamaño de N.
| No. Datos | Min (seg) | Max (seg) | Prom (seg) |
| 100 | 0.0018 | 0.0045 | 0.0029 |
| 500 | 0.0349 | 0.0443 | 0.0384 |
| 1000 | 0.1313 | 0.1434 | 0.1376 |
| 1500 | 0.2866 | 0.3154 | 0.2963 |
| 3000 | 1.1254 | 1.1634 | 1.1361 |
| 6000 | 4.3014 | 4.5207 | 4.4325 |
| 12000 | 16.3922 | 16.6072 | 16.4991 |
Los resultados anteriores son contrastados con los tiempos generados por un algoritmo que opera con 2 hilos o threads para determinar si se logran minimizar los tiempos obtenidos por un algoritmo secuencial tradicional. La tabla 3 muestra los tiempos obtenidos con la misma cantidad de los datos de entrada.
| No. Datos | Min (seg) | Max (seg) | Prom (seg) |
| 100 | 0.0005 | 0.0010 | 0.0008 |
| 500 | 0.0078 | 0.0336 | 0.0176 |
| 1000 | 0.0596 | 0.1206 | 0.1037 |
| 1500 | 0.2352 | 0.2864 | 0.2662 |
| 3000 | 1.0791 | 1.1649 | 1.1360 |
| 6000 | 4.2534 | 4.7678 | 4.4883 |
| 12000 | 15.3997 | 16.9756 | 16.6482 |
En la tabla 4 se muestran los tiempos generados por el algoritmo cuya ejecución se realiza a través de 3 hilos o threads.
| No. Datos | Min (seg) | Max (seg) | Prom (seg) |
| 100 | 0.0002 | 0.0005 | 0.0004 |
| 500 | 0.0034 | 0.0130 | 0.0083 |
| 1000 | 0.0141 | 0.0872 | 0.0474 |
| 1500 | 0.0358 | 0.1947 | 0.1599 |
| 3000 | 0.2759 | 0.7407 | 0.6748 |
| 6000 | 2.0629 | 3.0631 | 2.9489 |
| 12000 | 10.2179 | 11.9055 | 11.6512 |
De igual manera, la tabla 5 muestra los tiempos mínimos, máximos y promedio generados por el algoritmo cuyo procesamiento se realiza sobre cuatro hilos o threads.
| No. Datos | Min (seg) | Max (seg) | Prom (seg) |
| 100 | 0.00008 | 0.00031 | 0.00022 |
| 500 | 0.00189 | 0.01030 | 0.00561 |
| 1000 | 0.00758 | 0.05428 | 0.02681 |
| 1500 | 0.02232 | 0.14181 | 0.10350 |
| 3000 | 0.12018 | 0.57382 | 0.51995 |
| 6000 | 1.19436 | 2.27102 | 2.11490 |
| 12000 | 5.26838 | 9.13389 | 8.66902 |
Los tiempos obtenidos cuando los datos son ordenados mediante un proceso secuencial, a través de 2, 3 y 4 hilos o threads muestran menores tiempos conforme se emplean más threads. Los tiempos promedios son mostrados en la tabla 6.
| No. Datos | Prom (seg) | Prom 2 hilos (seg) | Prom 3 hilos (seg) | Prom 4 hilos (seg) |
| 100 | 0.0029 | 0.0008 | 0.0004 | 0.00022 |
| 500 | 0.0384 | 0.0176 | 0.0083 | 0.00561 |
| 1000 | 0.1376 | 0.1037 | 0.0474 | 0.02681 |
| 1500 | 0.2963 | 0.2662 | 0.1599 | 0.10350 |
| 3000 | 1.1361 | 1.1360 | 0.6748 | 0.51995 |
| 6000 | 4.4325 | 4.4883 | 2.9489 | 2.11490 |
| 12000 | 16.4991 | 16.6482 | 11.6512 | 8.66902 |
Dichos resultados son descritos de forma gráfica en las figuras 1, 2, 3, 4, 5, 6 y 7, en las cuales se contrastan los resultados obtenidos de un algoritmo secuencial (línea de color azul), los resultados obtenidos por un algoritmo que realiza el ordenamiento a través de dos hilos o threads (línea color rojo), los resultados obtenidos por tres hilos o threads (línea color gris); y por último, la línea de color amarillo representa los resultados obtenidos por el algoritmo cuando se emplean cuatro hilos o threads.
En las figuras 1, 2, 3, 4, 5, 6 y 7, el eje de las abscisas corresponde al número de pruebas hechas con el algoritmo. El eje de las ordenadas corresponde al tiempo empleado por el algoritmo para procesar los N números a ordenar.
Figura 1: Algoritmos con N=100
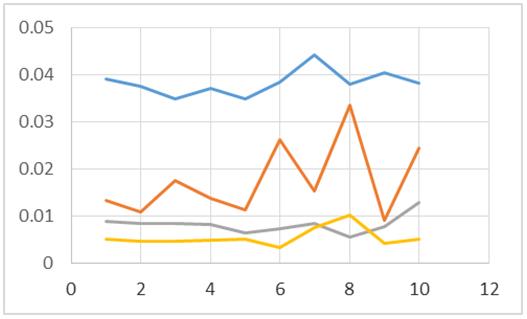
Figura 2: Algoritmos con N=500
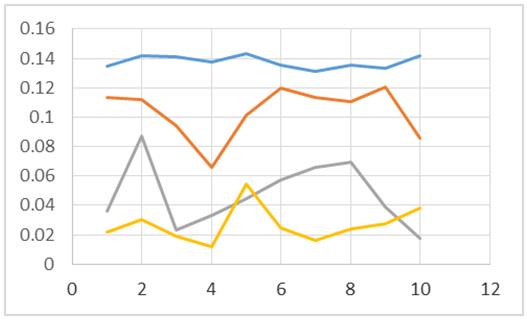
Figura 3: Algoritmos con N=1000
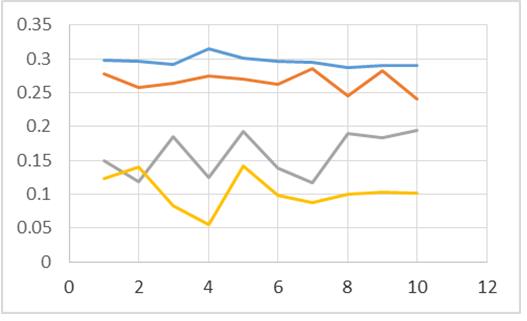
Figura 4: Algoritmos con N=1500
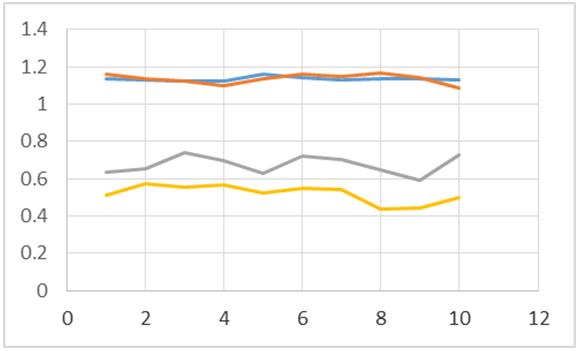
Figura 5: Algoritmos con N=3000
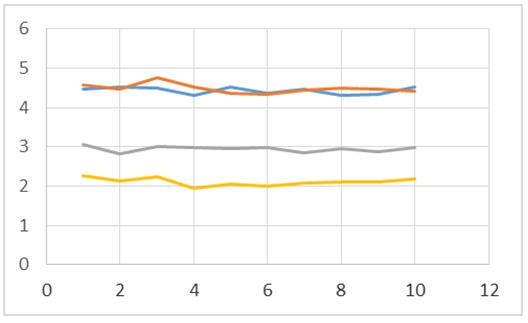
Figura 6: Algoritmos con N=6000
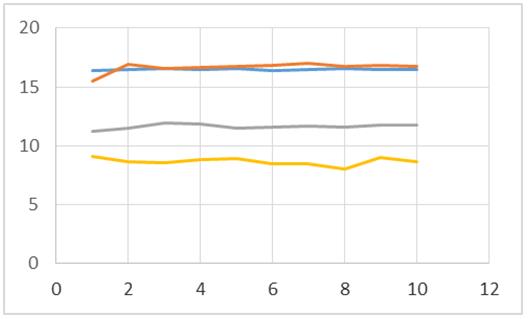
Figura 7: Algoritmos con N=12000
De acuerdo a las figuras 1, 2, 3 y 4 se puede apreciar que el algoritmo con dos threads resulta tener mejores tiempos al momento de ordenar 100, 300, 1000 y 1500 datos enteros (línea roja). Cosa contraria se obtiene al momento de ordenar 3000, 6000 y 12000 elementos, dado que se muestran mejores tiempos en algunas de las pruebas para el proceso que contiene un solo hilo de ejecución (línea color azul). Por lo tanto se puede inferir que conforme se incrementa el valor de N, es probable que el empleo de la concurrencia comience a resultar ineficiente para esta tarea en específico.
Nótese que en la figura 1 se muestra la ineficiencia en cuanto a al tiempo requerido por el proceso que solo cuenta con un solo hilo para procesar 100 y 500 números.
En las figuras 1, 2, 3, 4, 5, 6 y 7 resulta contundente que el proceso que utiliza 4 hilos para el procesado de los datos, tiene mejores tiempos de respuesta que los otros algoritmos, mostrando inclusive un mejor desempeño inclusive con el ordenamiento de los 12000 elementos.
Los resultados son mostrados la tabla 7, en la cual se listan los porcentajes de mejora en el desempeño del algoritmo en cuanto al tiempo de procesamiento de los N datos de entrada.
| No. datos | % 2 hilos | %3 hilos | %4 hilos |
| 100 | 72.23 | 86.19 | 92.39 |
| 500 | 54.09 | 78.31 | 85.39 |
| 1000 | 24.64 | 65.52 | 80.51 |
| 1500 | 10.15 | 46.04 | 65.07 |
| 3000 | 0.01 | 40.61 | 54.23 |
| 6000 | -1.26 | 33.47 | 52.29 |
| 12000 | -0.90 | 29.28 | 47.46 |
Es importante destacar que en la tabla 7 los porcentajes negativos denotan una pérdida de rendimiento en vez de obtener un beneficio en tiempo. La mejora de desempeño con respecto al tiempo de ejecución es visible cuando se emplean 3 y 4 hilos o threads, ya que los porcentajes obtenidos resultan ser mayores. La última columna de la tabla que corresponde al uso de 4 hilos resulta ser representativa por los porcentajes de mejora obtenidos.
Lo descrito anteriormente y los datos representados en la tabla 7 son vistos como gráfica en la figura 8.
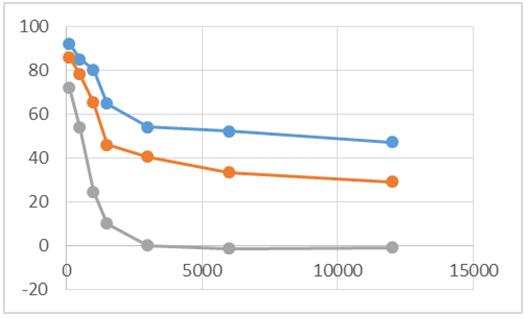
Figura 8: Desempeño de los algoritmos concurrentes
Como se muestra en la figura 8, la línea de color azul corresponde al desempeño obtenido al procesar los datos en 4 hilos o threads. La línea de color naranja corresponde al desempeño obtenido al procesar los datos en 3 hilos, y por último, la línea de color gris representa el desempeño mostrado por el algoritmo que tan solo emplea 2 hilos para procesar los datos de entrada.
El eje de las abscisas en la figura 8 corresponde al valor de N y el eje de las ordenadas corresponde al incremento en la mejora de los tiempos obtenidos al emplear 2, 3 y 4 hilos para procesar los datos de entrada. En la figura no se alcanza a apreciar la pérdida de desempeño que se obtiene al momento de manejar tan solo 2 hilos en el algoritmo, dicha pérdida es apreciada en la segunda columna de la tabla 7.
Los resultados obtenidos aún pueden ser mejorados de manera sorprendente con el empleo de múltiples hilos o threads al hacer uso de GPU’s ya que el poder de cómputo de estos dispositivos es mucho mayor ya que su aplicación está principalmente enfocada al despliegue gráfico en videojuegos y es tan grande el poder de cómputo que el hardware ya no es evaluado en el orden de los Hertz sino en términos de Flops, que corresponde a el número de operaciones que se pueden realizar en un segundo con datos cuyo tipo de dato es punto flotante.
De acuerdo a lo expuesto se nota una mejora significativa al incorporar el uso de hilos o threads cuando se requiere de hacer uso de operaciones repetitivas y que puedan ser procesadas concurrentemente o de manera paralela para la obtención de sus resultados.
De acuerdo a los resultados mostrados en la tabla 7 se hace evidente que el empleo de concurrencia en los algoritmos puede generar mejor desempeño en cuanto al tiempo requerido para completar una tarea.
Como trabajo futuro se pretende extender el algoritmo de tal forma que puedan emplearse más de dos threads, al igual que hacer uso del procesamiento en paralelo a través del empleo de GPU’s dado que el equipo de cómputo en el cual se realizaron las pruebas del presente artículo se encuentra dotado de una tarjeta NVIDIA GeForce GT 420M/PCIe/SSE2. Por lo tanto es posible llevar a cabo tareas paralelas a través de las cuales los porcentajes a obtener deberán ser mucho mejores a los mostrados por tareas concurrentes, ya que de acuerdo a las características de dicho GPU es posible manejar 1536 hilos o threads ejecutándose de manera paralela.
En lo que se refiere a descripción técnica del GPU a emplear para realizar la comparación en la mejora de tiempos, este posee un desempeño de 134.4 Gflops lo cual corresponde a realizar cientos de miles de operaciones de punto flotante en un solo segundo.
Una muestra de lo anterior se encuentra en el algoritmo para la suma de dos vectores. Se realizó la programación del algoritmo en el GPU antes mencionado logrando en 2 segundos la suma de un total de 500,000 números de punto flotante. Es por ello que dichos dispositivos son empleados para el cómputo de alto desempeño.
Corporation, N. (2007). Developer zone. Recuperado el 6 de Diciembre de 2014, de Link de acceso
González, R. (2012). Python para todos. España.
Peinado, F. (2010). LPS: Hilos y sincronización. Madrid, España.
[a]Escuela Superior de Tizayuca, Universidad Autónoma del Estado de Hidalgo
Tizayuca, Hidalgo, Cod Postal, México
Alonso Ernesto Solis: soliser@uaeh.edu.mx
Ernesto Flores: eflores@uaeh.edu.mx
José Carlos Quezada: jcarlos@uaeh.edu.mx